Table of contents
This time we’re picking up an old paper on infrastructure management for some large scale services at Microsoft. Our goal is to learn some of the core ideas in it and try to contrast how things may have changed.
Isard, Michael. “Autopilot: Automatic Data Center Management.” ACM SIGOPS Operating Systems Review 41, no. 2 (April 2007): 60–67. https://doi.org/10.1145/1243418.1243426.
Autopilot promises to automate software provisioning, deployment, monitoring and repair. The paper highlights a few benefits of automation: lower cost by replacing repetitive human actions with software, and higher reliability.
Principles
- Build on top of commodity hardware. Design software to provide for fault
tolerance.
- Use crash-only termination i.e. forced termination is the only exit path.
- Processes must tolerate crashes. This helps using retail asserts liberally.
- Assume non-byzantine failure model. Allow system to be reliable to run with partial availability/network partitions i.e. a subset of machines functional.
- Favor simplicity over efficiency and elegant. Few examples
- Store plain text config with code in same version control. Don’t depend on OS stores like registry.
- Config change deployment is same as code deployment.
- Assure correctness at all cost even if the solution tends to be complex. Correctness is matching the spec and explicit assumptions.
- Design new apps with automation in mind. Other expectations
- Crash-only termination.
- Use Autopilot APIs to report errors and benefit from automated error management and failover.
- Copy only deployment and config entirely specified in local file system.
Architecture
Topology
- Logical app specific definitions
- Each machine is assigned an app specific Machine Type or role, e.g. frontend, backend etc.
- A set of machines are put in a Scale Unit for deployment.
- Application racks consist of 20 identical multi-core machines each with 4
attached hard drives.
- Each rack has a switch for within rack communication
- Switch hierarchy to communicate with rest of data center (DC)
- Each computer has a management interface to allow remote upgrades and on/off
- Cluster consists of multiple racks. Largest cluster has 10s of thousand computers.
- DC consists of multiple clusters. Clusters are also failure boundaries.
Within a machine
- Autopilot windows services are pre-installed in the OS images.
- Filesync service used for file transfers between machines.
- Application manager ensures correct processes are running by reading the app manifest from Device Manager.
Within an app
- An app is packaged as a self-contained directory with a
start.batscript to run. - App shutdown happens through terminate process from the OS.
- Defines the Machine Types, and their configurations/packages.
System Components
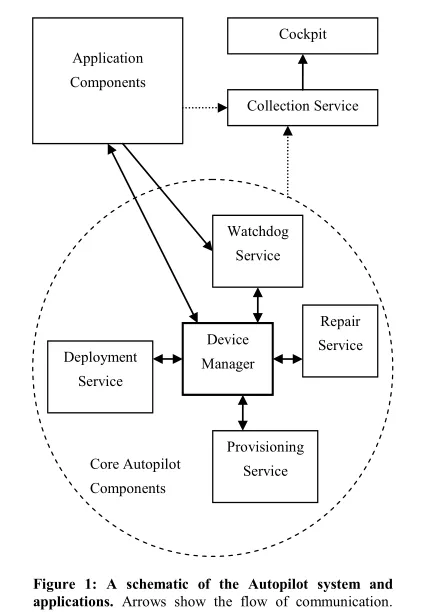
Autopilot chooses to keep the shared state small and strongly consistent with a quorum based mechanism in a few set of machines (5-10) in Device Manager.
- Device Manager (DM)
- Replicated state machine library to store ground truth state of the system.
- Uses paxos for consensus across replicas.
- Delegates the actions to keep cluster synchronized with ground truth to
other satellite services.
- Satellites pull state from Device Manager and update their/client state. Pull keeps the Device Manager lightweight without the need to track which satellites have received a state etc. (as in push model).
- Satellites keep state eventually consistent with Device Manager through heartbeats.
- Provisioning Service (PS)
- Replicated for redundancy, and a leader runs the actions.
- Probes network for new machines which have joined.
- Gets the desired state of the machine from DM and installs/boots/runs burn-in tests. Update state in DM.
- Deployment Service (DS)
- Replicated service that hosts the manifest directories with app files.
- Machines run a periodic task to connect to DM and fetch any missing manifests from a replica of the DS.
- Repair Service (RS)
- RS asks DM for machine status and runs the repair actions as instructed by DM.
- Note that DM decides how many and which machines are repaired, this allows the cluster to remain functional as a whole.
- Monitoring Services (MS)
- Collection Service (CS) aggregates counters and logs and dumps to a distributed file store
- Realtime counters are stored in SQL for low latency query
- Cockpit is a visualization tool to view counters aggregated per cluster
- Alert Service sends emails based on queries to Cockpit
Workflows
- Deployment
- New version of app is stored in DS
- DM is instructed to rollout. It adds the manifest to storage list for each
machine with required role. Kicks the machine to pull and deploy new
manifest.
- If a machine doesn’t get kicked, it will be updated through periodic task.
- Rollout proceeds in scale units for safety. Number of concurrent scale units is app defined. Within each scale unit, successful deployment is defined as a percent of machines upgraded.
- Fault detection and repair
- Machine is the unit of repair.
- Fault detection
- Watchdog probes are used. Report the result of probe to DM on a specific protocol.
- Machine is marked as error if any Watchdog reports a failure.
- Fault recovery
- Machine states: Healthy, Probation and Failure.
- Machine moved from H to P on deployment. Moves back to H if no errors, or to F otherwise.
- Recovery actions: Donothing, Reboot, Reimage, Replace. Action is chosen based on history and severity. E.g. reboot for non-fatal, Donothing if machines doesn’t have any recent F history.
- Metrics
- Apps and Autopilot dump counters on the local machine.
- CS collects these and writes onto a large scale distributed file store.
Application
Brief notes on an example Windows Live Search app in the Autopilot (AP) ecosystem.
- App implements custom fault tolerance on top of AP.
- App maintains a cache of machines in this cluster in each machine (peer info) and uses it to contact every other machine.
- App maintains list of failed machines (soft-failure list) other than the DM healthy list. This list can be based on the feedback at Load Balancer in the cluster (maintained by App).
- App maintains its monitoring service to monitor query feedback from constituent machines and uses it as a reliable Watchdog monitor for AP.
Lessons
- Keep checksums for artifacts, e.g. deployment manifests etc. since they will be corrupted. App level checksums complement the TCP/IP level checksums.
- Failure detectors must isolate overloading and failure; otherwise overloaded machines are marked as Failed and amplify the problem.
Historically, AP has been in development since the first deployments of Windows Live Search engine in 2004.