Let’s continue the discussion on mindful reading and capturing notes from the last note on Wiki, memos and a vault. Our current premise is the following.
Mindful reading builds knowledge. Binge reading is entertainment. Focus on the former.
Knowledge is a network of related thoughts - some preliminary and some matured with observations, experience and reinforcement.
Tools for thoughts help build the network allowing you to capture bits and pieces. Reviews reinforce the concepts.
Everything we read is a part of the knowledge graph.
The interesting hypothesis is this network already exists in our memory. We simply curate it mindfully using tools.
Here’s my current practice. This works reasonably well so far. All tools and data formats are open, will live forever and thus guarantee interoperability across other tools for thought.
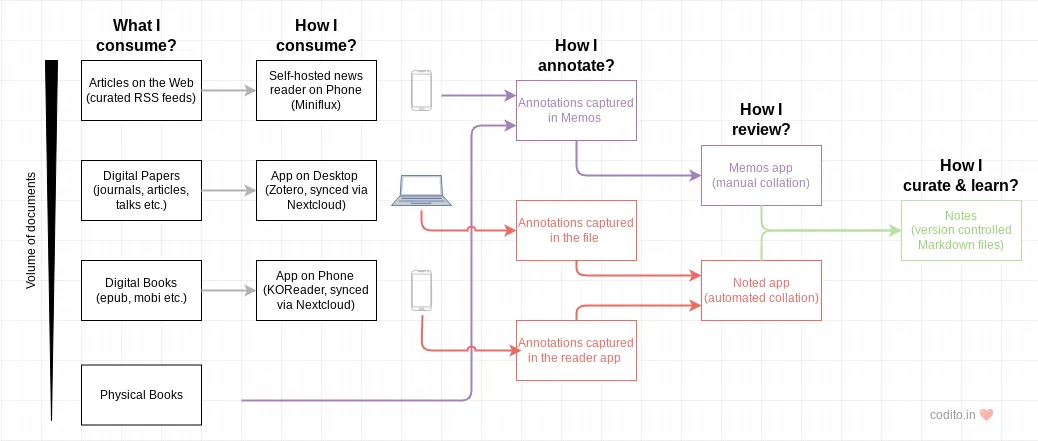
Some interesting patterns on consumption sources.
- Quantity of documents is in decreasing order from top to bottom. I read web articles more than papers or books.
- Quality of documents is also in decreasing order. Papers are thoughtful than articles on the web, and books are the most valuable source. Likely this order is a function of peer review and a higher bar for publishing from top to bottom.
For low quality and large volume documents, one-off or adhoc notes are probably good enough. I rarely derive more than two insights from a single article. More valuable sources are harder to consume in a single session, so annotations persist over days or weeks.
Why this matters? Adhoc notes can be organized with a loose taxonomy or tagging. Persistent notes require some kind of hierarchy since the topics are well-known 1.
Reader apps
- I use Miniflux for most of my web articles consumption. It has 493 feeds in 25 categories as of writing this note.
- For reading the journal papers, I use Zotero. I collect papers using firefox extension and categorize them in Zotero using both tags and folders. Built-in PDF readers works well. I export the document with embedded annotations. I sync the journal paper directory using Nextcloud.
- KOReader is my preferred book reader app. I used to run this in a jail-broken Kindle and now in an Android phone. Annotations are captured internally using KOReader’s native metadata format. I curate the set of books for an entire year and sync it on Nextcloud.
Since papers and books are synced on all devices, I never run out of things to read. No more excuses to binge read when waiting for a train or bus ride 🆒
Annotation and collation apps
- Articles on the web are annotated using Memos app on web or MoeMemos android app. I use tagging for this. Review happens every week to manually curate the annotations and add them to the knowledge base.
- I’m sticking to above for Physical Books too. Primarily because I don’t read many physical books, phone app is always available and other forms of note-taking are harder/complex to digitize.
- Digital book annotations from KOReader or PDF annotations from Zotero are automatically extracted into Markdown and aligned to the book chapters using our homegrown Noted app. These files are saved as-it-is in the knowledge base and I link them to other topics.
By the way, Noted recently got KOReader annotation extraction support. I’m wondering if we automate the Memos notes too someday.
Knowledge graph
This is just a set of Markdown files. 841 to be precise at the time of writing.
I primarily edit these using Neovim on the Desktop or Markor on the
phone. These use a folder structure for organization.
Version controlled and backed up in a remote git server. Additionally, synced
in Nextcloud too.
Maintaining these files are partially automated using linting (prettier) and authoring (Marksman - a markdown based LSP). A lot more is desired though. I’d like to build a topic modelling and reference/citation based tool someday along with a spaced repetition based quiz app. If you have ideas or suggestions, please do reach out.
To reading and wisdom 🍻
Footnotes
-
Your mileage may vary. Some of my friends prefer tagging more than hierarchy. Zettelkasten or similar schools of note-taking also support tagging as primary organization mechanism. ↩