Semantic search is based on the idea of matching a query with a corpus based on the intent or meaning. In contrast, the classic search algorithms compare text based on word frequencies1. We will explore the basics of semantic search using a pretrained model (distilbert) in this post. Second, our language of choice will be .NET core and the ML.net library in particular. We’ll also explore using Onnx to interacting with python models from .NET.
Code for this experiment is available in a github repo.
Game plan
We’ll pick a slightly modified version of TMDB 5k movies dataset from Kaggle2. Our goal is to develop a console app to find movies with plots similar to user input.
Core idea is to encode the movie plots using some model and generate vector embeddings for them. Next, we encode our query using the same mechanism. With both the corpus embedding and the query projected into the same vector space, similarity is finding the vectors which are nearest to the query vector. We’ll use a distance function for this purpose. Finally, we’ll convert back the vectors to the movies.
Where to start? Let’s find a model.
A model for that
Papers with code provides an excellent repository of papers and code organized into a neat taxonomy. The information retrieval task for instance lists the datasets, benchmarks along with the paper references. However, our goal is to reuse a model and preferably skip the resource intensive training phase.
Huggingface model repository was our next stop. Choose the sentence similarity task to filter models. Most of these models come from the excellent sentence transformers repository. Based on a quick guide on semantic search, we picked up the msmarco-distilbert-base-v3 model. It is based on DistilBERT fine tuned with the MSMARCO. DistilBERT is a smaller (~40%), cheaper and faster version of BERT. MSMARCO is a dataset of questions from Bing’s search logs and human answers.
Note that so far our experience is similar to picking up the right libraries. Identify the task and pick the appropriate model. Transformer models provide an abstraction to fine tune pretrained models for specific tasks by training on relevant datasets.
How do we use the model?
Interop
Huggingface page for the model provides sample python code for using the model. However, given our language choice (.NET), we must find another way.
We’ve seen similar problems in the engineering world. In the early days of .NET, it’s predecessor COM and C++ were popular. So, the CLR runtime provided capabilities to leverage the business logic in unmanaged (native) code. They called the feature interoperability. Key idea is to provide CLR services to marshal data back and forth between different runtimes, e.g. ensuring that other services like GC don’t interfere with memory allocations in the native world. We see similar patterns in the protocols too, e.g. REST, SOAP etc.
We’re looking for an interchange format. Search leads us to this announcement(2017) and to onnx. Is there a way to convert huggingface transformer models to onnx? Most important, can ML.net work with ONNX models? You bet!
First, let’s convert the huggingface model to ONNX. That’s a grand total of one function call.
from transformers.convert_graph_to_onnx import convert
from pathlib import Path
convert(framework="pt",
model="sentence-transformers/msmarco-distilbert-base-v3",
output="msmarco_distilbert.onnx", opset=11)What are the inputs and outputs of the model?
Inside the model
Let’s explore the ONNX model with https://netron.app. Upload the the onnx model.
Note that input_ids and attention_mask are the inputs, and output_0 is the
output.
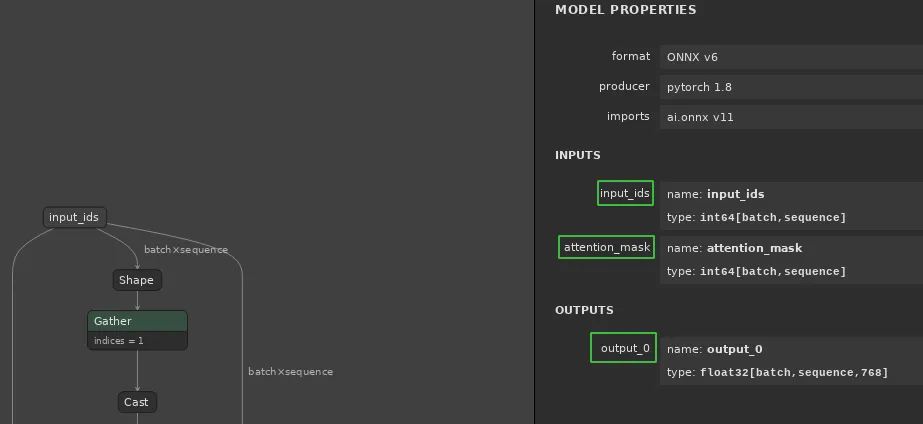
Our friends at huggingface explain the inputs in great
detail. A two line summary: input_ids are created by
tokenizing the input text using WordPiece tokenizer and attention_mask allows
specifying inputs of various length by padding every smaller input sequence with
extra 0. Code for tokenizer is available here. We create the
attention_mask by padding here. Inputs are represented by
DistilBertInput in our code. There are two dimensions: batch is the number
of inputs, and sequence is the encoding length.
Output of the model (the 0th layer) is the embedding for the input text. If you’re interested, this tutorial explains the BERT outputs in much more detail. Our output representation is simple.
Putting it together
All that remains is loading the ONNX model in ML.net and using it to generate the embeddings. Code for this logic is in DistilBert.GeneratorVectors.
First things first, ML.net provides ONNX integration through the
ApplyOnnxModel transformation. Pseudo code flow will be similar to below.
public TorchTensor GenerateVectors(IEnumerable<string> inputs)
{
// MLContext provides the core set of ML tasks and operations
var context = new MLContext();
// Prepare data using DataOperationsCatalog
IDataView data = context.Data.LoadFromEnumerable(...);
// Create a pipeline
var pipeline = context.Transforms.ApplyOnnxModel(...);
// Since onnx is a pretrained model, fitting is dummy
var model = pipeline.Fit(...);
// Tokenize and create attention masks for the input texts
var encodedInput = PrepareInput(inputs);
// Start inferring the encoded vectors
var engine = context.Model.CreatePredictionEngine<DistilBertInput,
DistilBertOutput>(...);
var predict = engine.Predict(encodedInput);
}Our first hurdle was specifying a set of text inputs i.e. a dynamic batch
size. The VectorType annotation in DistilBertInput doesn’t allow us to
specify it in runtime. Solution is to use a schema definition for input and
output.
// Onnx models do not support variable dimension vectors. We're using
// schema definitions to predict a batch.
// Input schema dimensions: batchSize x sequence
var inputSchema = SchemaDefinition.Create(typeof(DistilBertInput));
inputSchema["input_ids"].ColumnType =
new VectorDataViewType(
NumberDataViewType.Int64,
batchSize,
this.config.MaxSequenceLength);
inputSchema["attention_mask"].ColumnType =
new VectorDataViewType(
NumberDataViewType.Int64,
batchSize,
this.config.MaxSequenceLength);
// Onnx models may have hardcoded dimensions for inputs. Use a custom
// schema for variable dimension since the number of text documents
// are a user input for us (batchSize).
var inputShape = new Dictionary<string, int[]>
{
{ "input_ids", new[] { batchSize, this.config.MaxSequenceLength } },
{ "attention_mask", new[] { batchSize, this.config.MaxSequenceLength } }
};
var pipeline = mlContext.Transforms
.ApplyOnnxModel(
OutputColumnNames,
InputColumnNames,
modelPath,
inputShape,
null,
true);Setting up the onnx estimator for inference is similar to the pseudo code discussed above. See the implementation for details. Since we’re starting from zero, we implemented the logic in both python and .net to compare the output of each step side by side, and wrapped these into unit tests. See the python code here (tokenizer is also in same directory) and unit tests here.
Finally, we use mean pooling to down sample the output. The challenge here was to manipulate tensors and apply matrix operations in .NET. We figured that the TorchSharp library works the best. Below is the side by side python and C# code for mean pooling.
// https://github.com/codito/semanticsearch/blob/master/src/Models/Pooling.cs
public static TorchTensor MeanPooling(float[] embeddings, long[] attentionMask, long batchSize, long sequence)
{
var hiddenSize = 768L;
// See https://huggingface.co/sentence-transformers/msmarco-distilbert-base-v3#usage-huggingface-transformers
// Note how the python code below translates to dotnet, thanks to the
// awesome TorchSharp library.
//
// def mean_pooling(model_output, attention_mask):
// # First element of model_output contains all token embeddings
// token_embeddings = model_output[0]
// input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
// sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
// sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
// return sum_embeddings / sum_mask
var tokenEmbeddings = Float32Tensor.from(
embeddings,
new[] { batchSize, sequence, hiddenSize });
var attentionMaskExpanded = Int64Tensor.from(
attentionMask,
new[] { batchSize, sequence })
.unsqueeze(-1).expand(tokenEmbeddings.shape).@float();
var sumEmbeddings = (tokenEmbeddings * attentionMaskExpanded).sum(new[] { 1L });
var sumMask = attentionMaskExpanded.sum(new[] { 1L }).clamp(1e-9, float.MaxValue);
return sumEmbeddings / sumMask;Lack of torchsharp documentation was an initial hurdle that required a bit of
trial and error (again with the python interpreter running on the side to ensure
we’re using the right op). Two interesting callouts here. First, which library
to use for tensors? TorchSharp provides TorchTensor and ONNX provides
DenseTensor. Then there are libraries like GenericTensor. TorchTensor is
awesome if you want to leverage the pytorch algorithms. Second, how do we
convert from TorchTensor to regular arrays?
// Create TorchTensor using factories
var tensor = Float32Tensor.from(float[] inputArray, int[] dimensions);
// Convert tensor back to 1d array
// Note that Data<float> is a Span, view over the unmanaged memory
var array = tensor.Data<float>().ToArray();Since TorchSharp is a wrapper on the pytorch C++ library, we had to search the python docs https://pytorch.org/docs/stable/index.html followed by https://pytorch.org/cppdocs/ to find the relevant APIs. Beware that the torchsharp nuget packages are huge since they include the CUDA libraries; there’s a way to use the system installed libtorch for p/invokes, but Arch Linux has a later version, we didn’t proceed with building the one used by TorchSharp from AUR.
It is worth mentioning the failed attempts. Our initial approach was to use NumSharp for computing mean pooling by using the familiar NumPy APIs. However, the operations were slower and the outputs didn’t match with the side by side pytorch code.
Switching back to our game plan. Now that we have the vectors generated for the input text and the query, similarity matching is simply finding the cosine distance between the tensors. See the below code.
// https://github.com/codito/semanticsearch/blob/master/src/Models/Similarity.cs
public static class Similarity
{
public static (TorchTensor Values, TorchTensor Indexes) TopKByCosineSimilarity(
TorchTensor corpus,
TorchTensor query,
int limit)
{
// Cosine similarity of two tensors of different dimensions.
// cos_sim(a, b) = dot_product(a_norm, transpose(b_norm))
// a_norm and b_norm are L2 norms of the tensors.
var corpusNorm = corpus / corpus.norm(1).unsqueeze(-1);
var queryNorm = query / query.norm(1).unsqueeze(-1);
var similar = queryNorm.mm(corpusNorm.transpose(0, 1));
// Compute top K values in the similarity result and return the
// values and indexes of the elements.
return similar.topk(limit);
}
}After we find the top K similar tensors, we use the indexes array to find the
relevant text and print it. You can find the end to end logic here.
It was a fun exercise to learn the mental model of ML.net, using a pretrained model with ONNX and finally, leveraging the Pytorch APIs with TorchSharp. A future experiment is to try persisting the vectors to disk and using ANN like algorithms to search.
Footnotes
-
BM25 algorithm comes to mind. It is based on frequency of terms appearing in the documents. No weightage is given to the order or proximity of the terms. Developed four decades back, I believe the BM25 algorithm continues to be popular and is the default similarity algorithm in Elastic Search. ↩
-
Original dataset has serialized json for python dict, list etc. which don’t play well with ML.net
IDataViewout of the box. We cleaned and transformed it to only the relevant fields: title, overview, genres and keywords. ↩